VFL FFNet Model Training
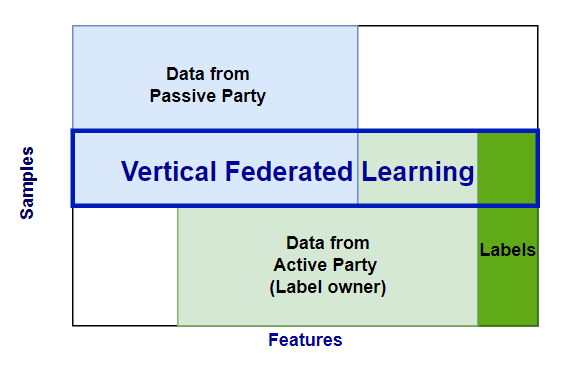
In a vertical federated learning (VFL) process, two or more parties collaboratively train a model using datasets that share a set of overlapping features. Each party has partial information about the overlapped subjects in the dataset. Therefore, before running a VFL training session, a private record linkage (PRL) session is performed to find the intersection and create alignment between datasets.
There are two types of parties participating in the training:
The Active Party owns the labels, and may or may not also contribute data.
The Passive Party contributes only data.
For example, in data sharing between a hospital (party B, the Active party) and a medical imaging centre (party A, the Passive party), only a subset of the hospital patients will exist in the imaging centre's data. The hospital can run a PRL session to determine the target subset for VFL model training.
VFL Session Overview
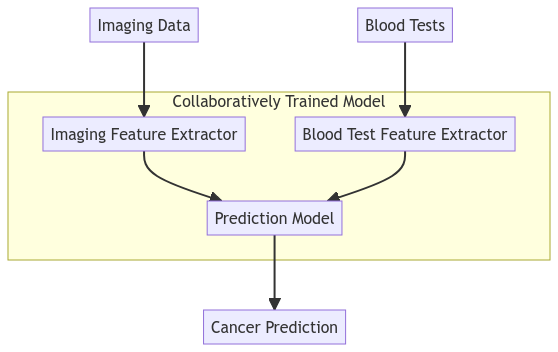
A hospital may have patient blood tests and outcome information on cancer, but imaging data is owned by an imaging centre. They want to collaboratively train a model for cancer diagnosis based on the imaging data and blood test data. The hospital (active party) would own the outcome and patient blood tests and the Imaging Centre (passive party) would own the imaging data.
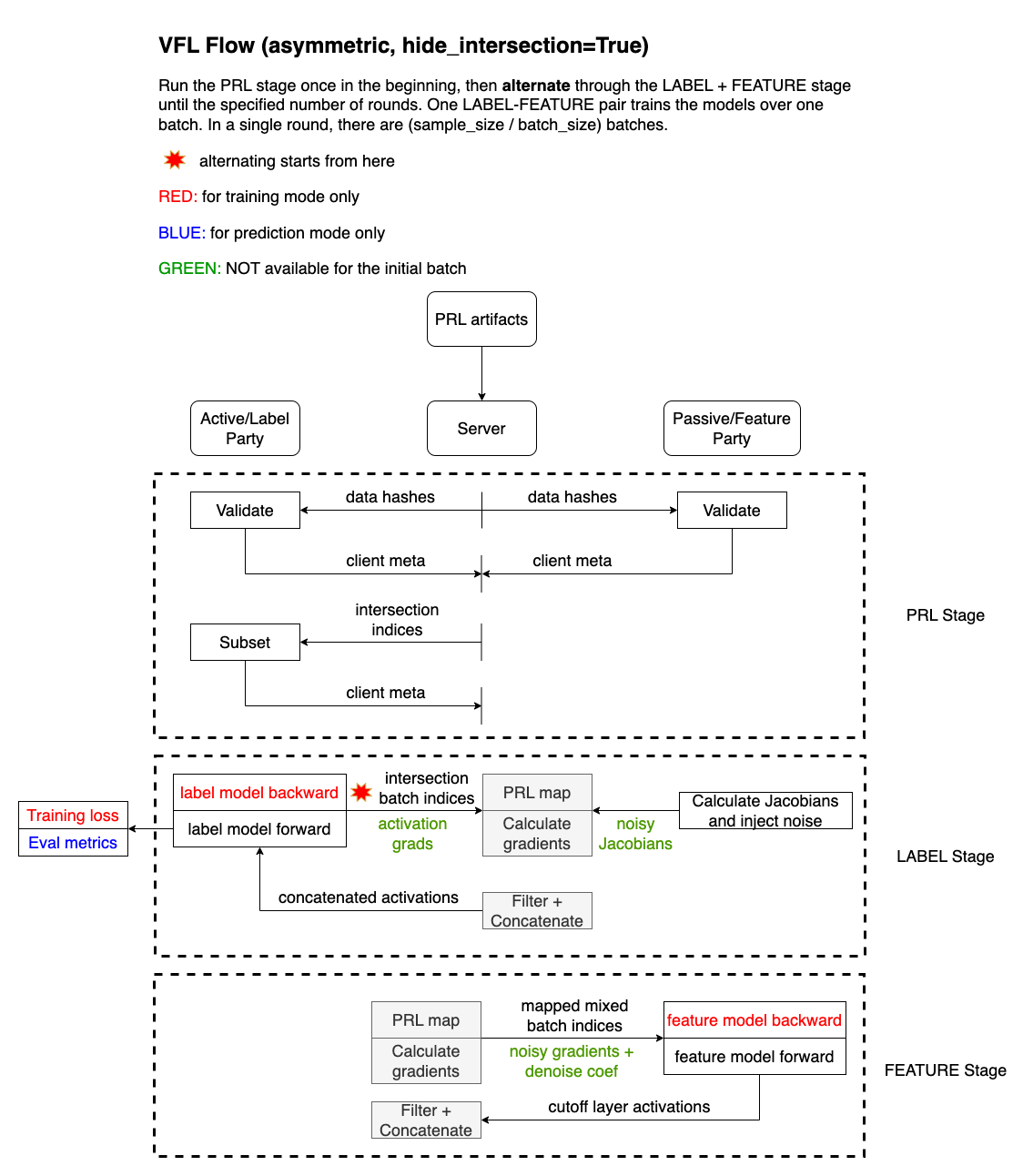
A simplified model of the process is shown below.
integrate.ai VFL Flow
The following diagram outlines the training flow in the integrate.ai implementation of VFL.
VFL Training Session Example
Use the integrateai_fargate_batch_client_vfl.ipynb notebook to follow along and test the examples shown below by filling in your own variables as required.
The notebook demonstrates both the PRL session and the VFL train and predict sessions.
This example uses AWS Fargate and Batch to run the session.
Complete the Environment Setup.
Ensure that you have the correct roles and policies for Fargate and Batch. See Using AWS Batch with integrate.ai and Running a training server on AWS Fargate for details.
Run a PRL session to obtain the aligned dataset. This session information is required for the VFL training session. Note: The sample notebook demonstrates running the PRL session and VFL sessions in the same flow. However, if you have already run a successful PRL session, you could instead provide that session ID to the VFL
trainsession directly.Create a
model_configand adata_configfor the VFL session.
Arguments:
strategy: Specify the name and parameters. For VFL, the strategy is
SplitNN.This strategy accepts an optional parameter
hide_intersection. If set toTrue, the intersection membership information is hidden from passive parties.
model: Specify the
feature_modelsandlabel_model.feature_modelsrefers to the part of the model that transforms the raw input features into intermediate encoded columns (usually hosted by both parties).label_modelrefers to the part of the model that connects the intermediate encoded columns to the target variable (usually hosted by the active party).
ml_task: Specify the type of machine learning task, and any associated parameters. Options are
classificationorregression.optimizer: Specify any optimizer supported by PyTorch.
seed: Specify a number.
Create and start a training session
Create a VFL training session.
Specify the PRL session ID and ensure that the vfl_mode is set to train.
Set up the task builder and task group
In the sample notebook, the server and client task builders are set up in the PRL session workflow, so you only have to create the VFL task group.
If you are not using the notebook, ensure that you import the required packages from the SDK, and create a server and client task builder.
Create a task in the task group the server, and for each client. The number of client tasks in the task group must match the number of clients specified in the data_config used to create the session.
The following parameters are required for each client task:
train_pathtest_pathbatch_sizestorage_pathclient_name
The vcpus and memory parameters are optional overrides for the job definition.
Monitor submitted jobs
Each task in the task group kicks off a job in AWS Batch. You can monitor the jobs through the console or the SDK.
When the session completes successfully, "True" is returned. Otherwise, an error message appears.
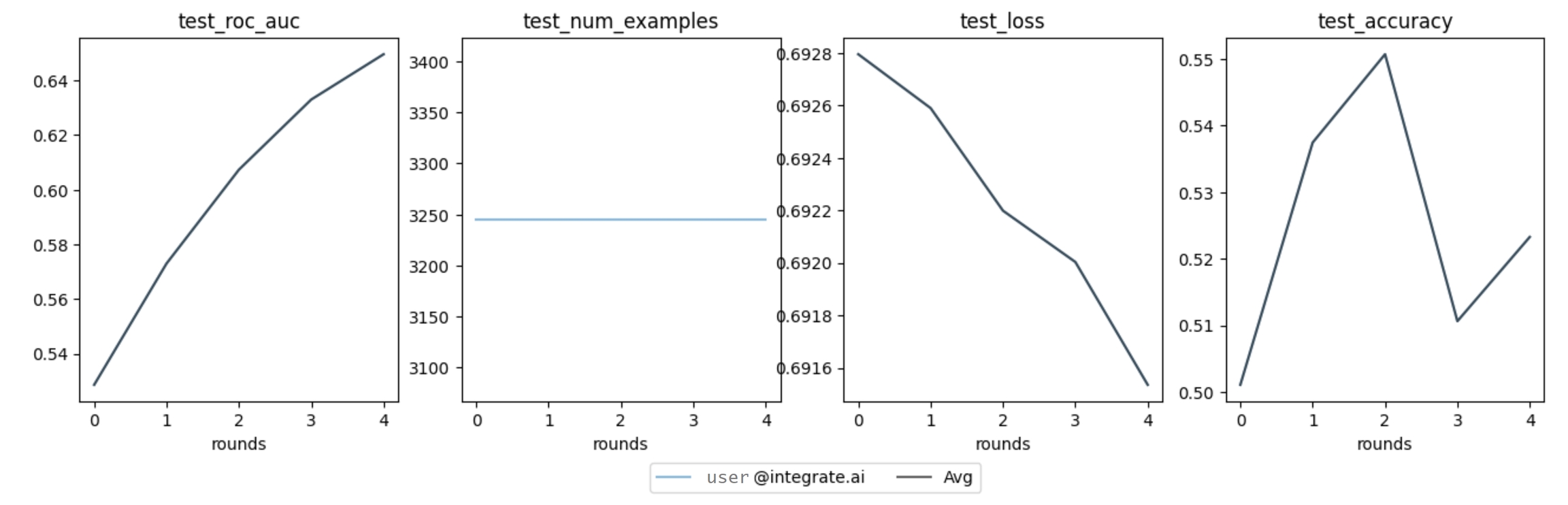
View the training metrics
Once the session completes successfully, you can view the training metrics.
Example of plotted training metrics
VFL Prediction Session Example
Create and start a prediction session
To create a VFL prediction session, specify the PRL session ID (prl_session_id) and the VFL train session ID (training_session_id).
Set the vfl_mode to predict.
Specify the full path for the storage location for your predictions, including the file name.
Create and start a task group for the session.
Monitor submitted jobs
Each task in the task group kicks off a job in AWS Batch. You can monitor the jobs through the console or the SDK.
When the session completes successfully, "True" is returned. Otherwise, an error message appears.
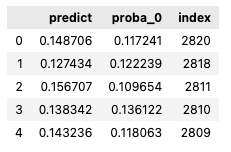
View VFL Predictions
View the predictions from the Active party and evaluate the performance.
Example output:
Example output:
Last updated