HFL Gradient Boosted Models (HFL-GBM)
An overview of the integrate.ai implementation of GBM for HFL
Gradient boosting is a machine learning algorithm for building predictive models that helps minimize the bias error of the model. The gradient boosting model provided by integrate.ai is an HFL model that uses the sklearn implementation of HistGradientBoostingClassifier for classifier tasks and HistGradientBoostingRegresssor for regression tasks.
The GBM sample notebook (integrateai_api_gbm.ipynb) provides sample code for running the SDK, and should be used in parallel with this tutorial. This documentation provides supplementary and conceptual information to expand on the code demonstration.
Prerequisites
Complete the Environment Setupfor your local machine.
Open the
integrateai_api_gbm.ipynbnotebook to test the code as you walk through this tutorial.
Review the sample Model Configuration
integrate.ai has a model class available for Gradient Boosted Models, called iai_gbm. This model is defined using a JSON configuration file during session creation.
The
strategyfor GBM isHistGradientBoosting.You can adjust the following parameters as needed:
max_depth- Used to control the size of the trees.learning_rate- (shrinkage) Used as a multiplicative factor for the leaves values. Set this to one (1) for no shrinkage.max_bins- The number of bins used to bin the data. Using less bins acts as a form of regularization. It is generally recommended to use as many bins as possible.sketch_relative_accuracy- Determines the precision of the sketch technique used to approximate global feature distributions, which are used to find the best split for tree nodes.
Set the machine learning task type to either
classificationorregression.Specify any parameters associated with the task type in the
paramssection.
The
save_best_modeloption allows you to set the metric and mode for model saving. By default this is set toNone, which saves the model from the previous round, andmin.
Example model configuration JSON:
The notebook also provides a sample data schema. For the purposes of testing GBM, use the sample schema, as shown below.
For more about data schemas, see Create a Custom Data Loader.
Create and run a GBM training session
Federated learning models created in integrate.ai are trained through sessions. You define the parameters required to train a federated model, including data and model configurations, in a session.
Create a session each time you want to train a new model.
The following code sample demonstrates creating and starting a session with two training clients (two datasets) and ten rounds (or trees). It returns a session ID that you can use to track and reference your session.
| Argument (type) | Description |
|---|---|
| Name to set for the session |
| Description to set for the session |
| Number of clients required to connect before the session can begin |
| Number of rounds of federated model training to perform. This is the number of trees to train. |
| Name of the model package to be used in the session. For GBM sessions, use |
| Name of the model configuration to be used for the session |
| Name of the data configuration to be used for the session |
Start the training session
The next step is to join the session with the sample data. This example has data for two datasets simulating two clients, as specified with the min_num_clients argument. Therefore, to run this example, you will call subprocess.Popen twice to connect each dataset to the session as a separate client.
The session begins training once the minimum number of clients have joined the session.
Each client runs as a separate Docker container to simulate distributed data silos.
If you extracted the contents of the sample file to a different location than the default, change the data_path in the sample code before attempting to run it.
Example:
where
data_pathis the path to the sample data on your local machineIAI_TOKENis your access tokentraining_session.idis the ID returned by the previous steptrain-pathis the path to and name of the sample dataset filetest-pathis the path to and name of the sample test filebatch-sizeis the size of the batch of dataclient-nameis the unique name for each client
Poll for Session Results
Sessions take some time to run. In the sample notebook and this tutorial, we poll the server to determine the session status.
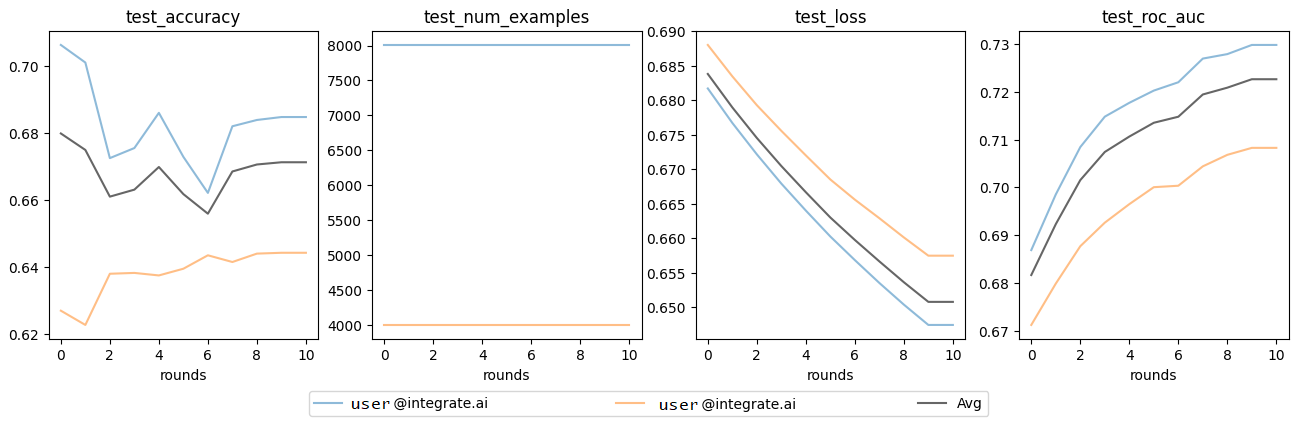
View the training metrics
After the session completes successfully, you can view the training metrics and start making predictions.
Retrieve the model metrics
as_dict.Plot the metrics.
Example plots:
Load the test data
Convert test data to tensors
Run model predictions
Result: array([0, 1, 0, ..., 0, 0, 1])
Result: 0.7082738332738332
When the training sample sizes are small, this model is more likely to overfit the training data.
Last updated