An overview and example of a linear inference model for performing tasks such as GWAS in HFL
The built-in model package iai_linear_inference trains a bundle of linear models for the target of interest against a specified list of predictors. It obtains the coefficients and variance estimates, and also calculates the p-values from the corresponding hypothesis tests. Linear inference is particularly useful for genome-wide association studies (GWAS), to identify genomic variants that are statistically associated with a risk for a disease or a particular trait.
This is a horizontal federated learning (HFL) model package.
The integrateai_linear_inference.ipynb, located in the sample-notebook folder of the SDK package, demonstrates this model package using the sample data that is available for download from the integrate.ai web dashboard.
Follow the instructions in the Environment Setup section to prepare a local test environment for this tutorial.
Overview of the iai_linear_inference package
There are two strategies available in the package:
LogitRegInference - for use when the target of interest is binary
LinearRegInference - for use when the target is continuous
Example model_config for a binary target:
model_config_logit ={"strategy":{"name":"LogitRegInference","params":{}},"seed":23,# for reproducibility}
The data_config dictionary should include the following three fields.
target: the target column of interest
shared_predictors: predictor columns that should be included in all linear models. For example, the confounding factors like age, gender in GWAS.
chunked_predictors: predictor columns that should be included in the linear model one at a time. For example, the gene expressions in GWAS.
The columns in all the fields can be specified as either names/strings or indices/integers.
With this example data configuration, the session trains four logistic regression models with y as the target, and x1, x2 plus any one of x0, x3, x10, x11 as predictors.
Create a training session
For this example, there are two (2) training clients and the model is trained over five (5) rounds.
training_session_logit = client.create_fl_session( name="Testing linear inference session", description="I am testing linear inference session creation through a notebook", min_num_clients=2, num_rounds=5, package_name="iai_linear_inference", model_config=model_config_logit, data_config=data_config_logit,).start()training_session_logit.id
Ensure that you have downloaded the sample data. If you saved it to a location other than your Downloads folder, specify the data_path to the correct location.
data_path ="~/Downloads/synthetic"
Start the training session
This example demonstrates starting a training session locally. The clients joining the session are named client-1-inference and client-2-inference, respectively.
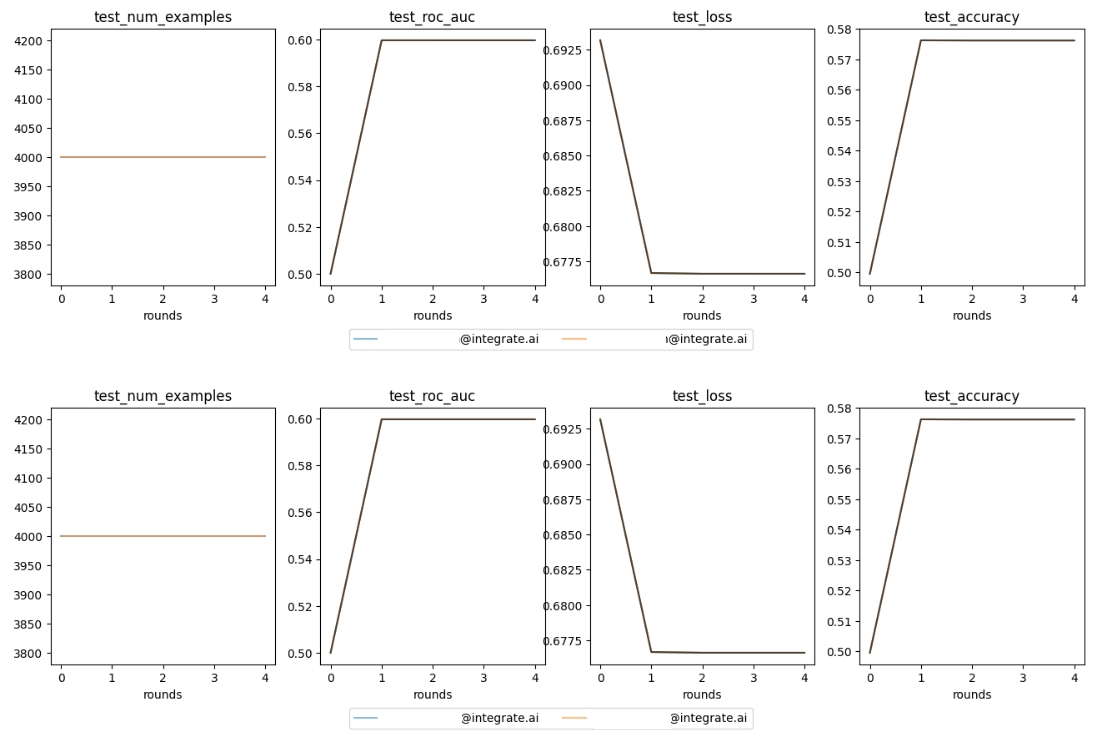
Once the session is complete, you can view the training metrics and model details such as the model coefficients and p-values. In this example, since there are a bundle of models being trained, the metrics are the average values of all the models.
The LinearInferenceModel object can be retrieved using the model's as_pytorch method. And the relevant information such as p-values can be accessed directly from the model object.
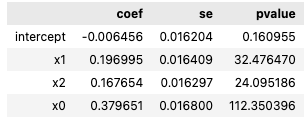
The .summary method fetches the coefficient, standard error, and p-value of the model corresponding to the specified predictor.
summary_x0 = model_logit.summary("x0")summary_x0
Example output:
Making predictions
You can also make predictions with the resulting bundle of models when the data is loaded by the ChunkedTabularDataset from the iai_linear_inference package. The predictions will be of shape (n_samples, n_chunked_predictors) where each column corresponds to one model from the bundle.